Team FRMA Matthew Johnson // Alexander Schwartzberg // John Angel // Jordan Faas-Bush // Andrew Gaudet
I. Use Case Description | |
Use Case Name | Facial Recognition Model Analyzer |
Use Case Identifier | 1 |
Source | |
Point of Contact | Matthew Johnson, johnsm21@rpi.edu Alexander Schwartzberg, schwaa6@rpi.edu John Angel, angelj3@rpi.edu Jordan Faas-Bush, faasbj@rpi.edu Andrew Gaudet, gaudea@rpi.edu |
Creation / Revision Date | September 22, 2018 |
Associated Documents | https://tw.rpi.edu/web/Courses/Ontologies/2018/FRMA |
II. Use Case Summary | |
Goal | Machine learning allows us to learn a model for a given task such as facial recognition with a high degree of accuracy. However, after these models are generated they are often treated as black boxes and the limitations of a model are often unknown to the end user. The system developed for this use case will provide an intuitive interface to explore the limits of a facial recognition model by semantically integrating “smart” images(semantically describe who the image depicts and what Kumar [2] features the image exhibits) with classification results to discover common causes for misclassifications. |
Requirements |
|
Scope | The scope for this use case is limited to the LFW dataset, the LFW ground truth [1] and a single facial recognition model FaceNet [2]. In addition, we will only consider image attributes learned in Kumar et al. paper [3]. |
Priority | Identify the priority of the use case (with respect to other use cases for the project) |
Stakeholders | Machine Learning Researchers- Did your new methodology develop a model that covers the training domain specifically or can it be easily transferred to new domains? Application Engineer or Program Manager- You have ten different machine learning models you could include in your product and no test data; how do you choose which to include? |
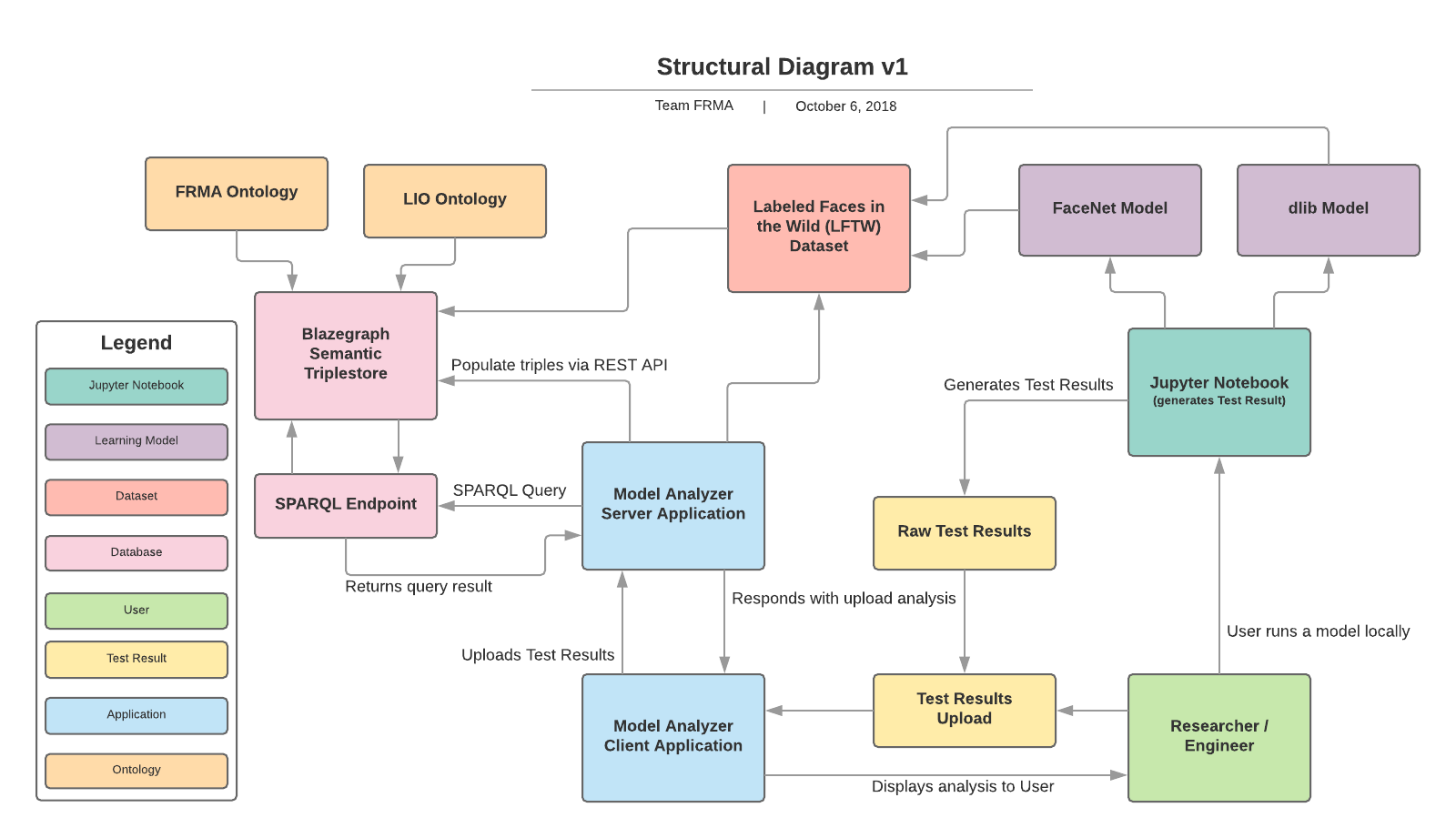
Description | The use case is focused on requirements for the development of an application to support facial recognition model analysis. It will be used to discover how an ontology of image attributes correlate to the test results of a facial recognition model. The application must be able to read in model test results provided by a user and link classification results to known “smart” images which have a hierarchical ontology of visual features describing the image content. Using this alignment between datasets the system will be able to calculate accuracy statistics across images attributes and find correlations between misclassifications and image attributes. The system will present this information as a semantically enhanced hierarchy view of attributes with the statistics of all images that contain that attribute (i.e ‘has goatee’) or belong under an attribute category (i.e. ‘has facial hair’). When a user selects a level on this category they will be presented with a view showing the images associated with that category and an indication of whether they were classified correctly or not. In addition, the user should be able to switch between all images, correctly classified images, and misclassifications which cause the hierarchy view to update statistics and the images presented. |
Actors / Interfaces | Researcher/Engineer (person who wants to know more about a model) Labeled Faces in the Wild Dataset [1] The test results of the model being evaluated. |
Pre-conditions | The system must have the image attributes lifted into RDF and aligned with the feature ontology. The model results that the user is inputting into the system must have used the LFW dataset as their training dataset. |
Post-conditions | Postconditions (Success) - The user loads their model’s test results into the Model Analyzer to generate a hierarchical view of misclassifications and notices that model misclassified facial hair the most and examines the various misclassified photos. Postconditions (Failure) - The user tries to load their model’s test results into the Model Analyzer, but the file format was incorrect. As a result, the user was unable to generate a hierarchical view. |
Triggers | A user submits the test results for a model and selects the model from which the results were generated, or a user selects a previously uploaded test result set. |
Performance Requirements | List any known performance-specific requirements – timing and sizing (volume, frequency, etc.), maintainability, reusability, other “-ilities”, etc. |
Assumptions | Image attributes will correlate with the performance of the model being examined. Past experiments have shown that image factors such as quality and facial occlusion reduce the accuracy of facial recognition [5], but there’s no guarantee the facenet classification results will reflect that. |
Open Issues | |
III. Usage Scenarios
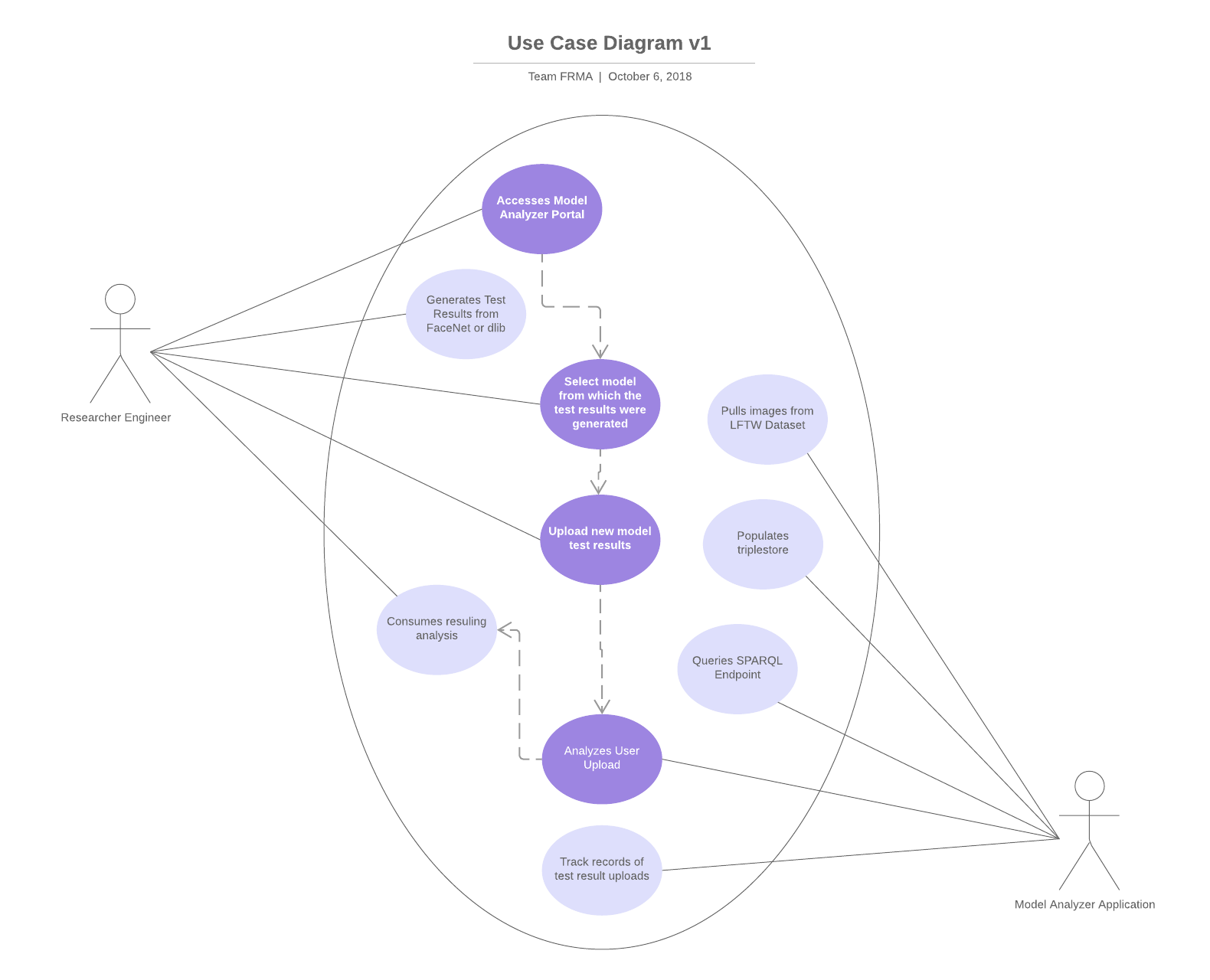
A user wants to learn the limitations of their new facial recognition model, so they run the model against a test set and capture the classification result of each picture in a CSV file. The user then takes this file and imports it into the Model Analyzer web portal and chooses the dataset the model was run against. The system then lifts the results into RDF and links each test result to a “smart” image which has the image attributes described in an ontology. The system then generates a semantically enhanced hierarchy view of attributes with the classification accuracy of images that contain that attribute. The user then switches the system from ‘all’ to ‘misclassification only’ and the hierarchy view updates to show attribute misclassification accuracy. From this view the user notices that the model misclassifies images with facial hair the most and clicks on this level of the hierarchy. The portal than populates the screen with the test images from that attribute level that were misclassified, allowing further investigation.
A user wants to know if their previously analyzed facial recognition model would do well on images with poor lighting. The user opens the Model Analyzer web portal and chooses a previously run data model from the list. The system then loads in the previous results into RDF and links each test result to a “smart” image which has the image attributes described in an ontology. The system then generates a semantically enhanced hierarchy view of attributes with counts of the number of images that contain that attribute. From this view the user selects both the harsh lighting and soft lighting image attributes. The portal then populates the screen with the test images that contain either of those attributes and a combined accuracy. The user leverages this accuracy figure to conclude that their old model will work well in poor lighting conditions.
IV. Basic Flow of Events
Basic / Normal Flow of Events | |||
Step | Actor (Person) | Actor (System) | Description |
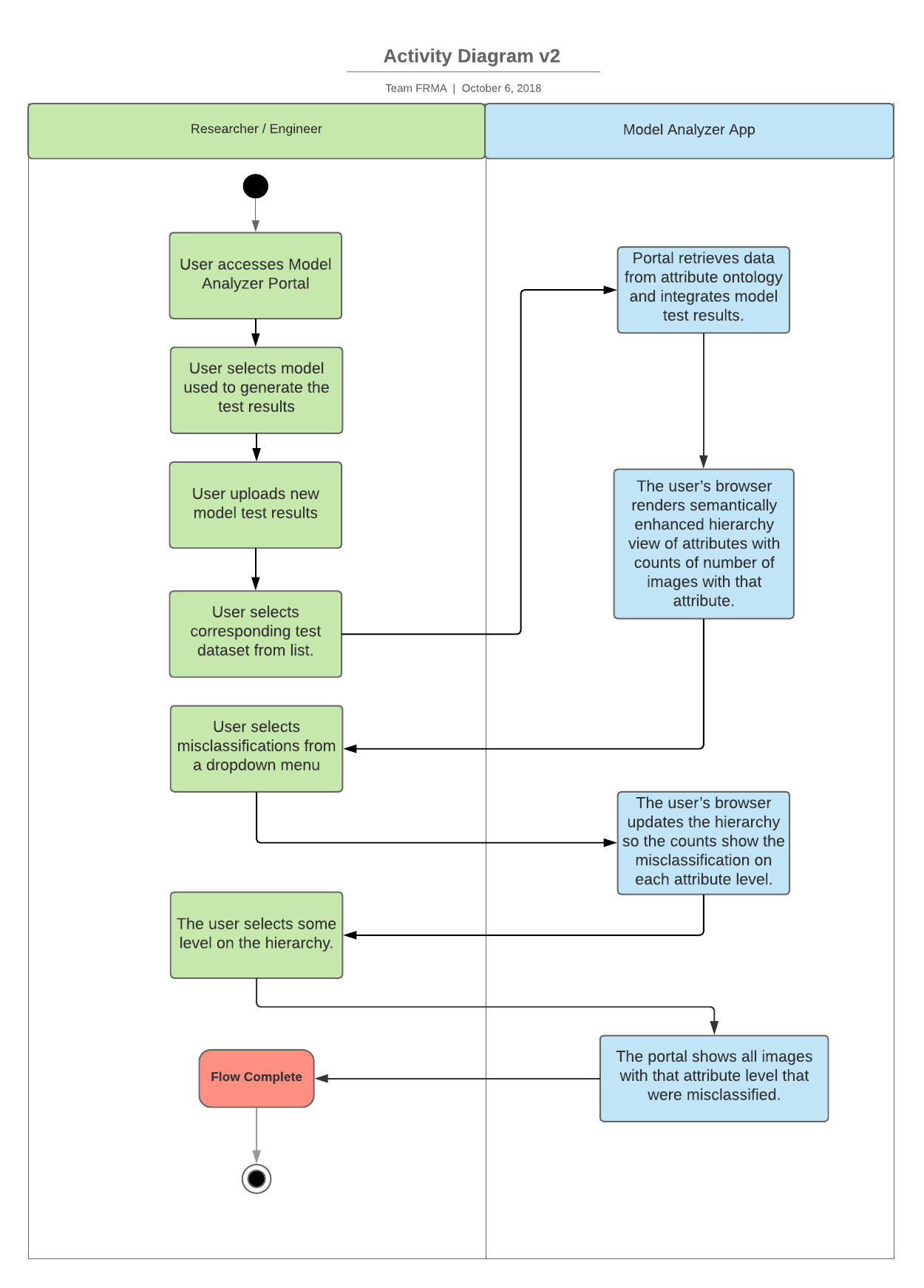
1 | Researcher/Engineer | User accesses Model Analyzer portal | |
2 | Researcher/Engineer | User selects model used to generate test results (FaceNet, dlib) | |
2 | Researcher/Engineer | User uploads new model test results | |
3 | Researcher/Engineer | User selects corresponding test dataset from list. | |
4 | Model Analyzer App | Portal retrieves data from attribute ontology and integrates model test results | |
5 | Model Analyzer App | The user’s browser renders a semantically enhanced hierarchy view of attributes with counts of number of images with that attribute. The system will use the ground truth data in the LFW Attributes dataset to associate images used in the user’s test results to Kumar[2] attributes. Then it would simply count the occurrences of attributes in the users test results. Additional note: the “hierarchy view” structure is directly taken from the attribute ontology that we will be building. | |
6 | Researcher/Engineer | User selects misclassifications from a dropdown menu | |
7 | Model Analyzer App | The user’s browser updates the hierarchy so the counts show the misclassification on each attribute level. The system accomplishes this by first accessing the ground truths within the LFW dataset and comparing them to the inputted test results to obtain which images were correctly identified in the test results. This information refined by an inference rule that compares the TestResult with the ground truth and assert if the model classified the image correctly.. The system will then take this information and combine it with the LFW Attributes dataset’s ground truths to associate those test results to image attributes. From here only results that were misclassified will be shown. | |
8 | Researcher/Engineer | The user selects some level on the hierarchy. | |
9 | Model Analyzer App | The portal shows all images with that attribute level that were misclassified. This will be accomplished through similar logic to step 7 with the exception that only results of a certain level’s class will be show. | |
V. Alternate Flow of Events
Alternate Flow of Events | |||
Step | Actor (Person) | Actor (System) | Description |
1 | Researcher/Engineer | User accesses Model Analyzer portal. | |
2 | Researcher/Engineer | User selects model used to generate test results (FaceNet, dlib) | |
2 | Researcher/Engineer | User selects previously uploaded model test results. | |
3 | Researcher/Engineer | User selects corresponding test dataset from list. | |
4 | Model Analyzer App | Portal retrieves data from attribute ontology and integrates model test results. | |
5 | Model Analyzer App | The user’s browser renders semantically enhanced hierarchy view of attributes, which displays a tree view showing top level image characteristic such as lighting variation, depicted person attributes, along with mid-level attributes such as wearables, and low level attributes like hats. An example tree is shown in the notes section below. Across each level of this tree we will collect counts of number of images with that attribute. The system will use the ground truth data in the LFW Attributes dataset to associate images used in the user’s test results to Kumar attributes. Then it would simply count the occurrences of attributes in the users test results. Additional note: the “hierarchy view” structure is directly taken from the attribute ontology that we will be building. | |
6 | Researcher/Engineer | User selects misclassifications from a dropdown menu | |
7 | Model Analyzer App | The user’s browser updates the hierarchy so the counts show the misclassification on each attribute level. The system accomplishes this by first accessing the ground truths within the LFD dataset and comparing them to the inputted test results to obtain which images were correctly identified in the test results. This information refined by some inference rules will give which images were misclassified. For example if we get a test result that says image 203 is Steve Irwin, we can perform a query to get the ground truth data on image 203 and if that image depicts Steve Irwin, we will assert a new triple saying that the classification result is correct.The system will then take this information and combine it with the LFW Attributes dataset’s ground truths to associate those test results to image attributes. From here only results that were misclassified will be shown. | |
8 | Researcher/Engineer | The user selects some level on the hierarchy. | |
9 | Model Analyzer App | The portal shows all images with that attribute level that were misclassified. This will be accomplished through similar logic to Step 7 with the exception that only results of a certain level’s class will be shown. An example of what the hierarchy view will look like is shown in the notes section. | |
VI. Use Case and Activity Diagram(s)
VII. Competency Questions
Q: What type of image attributes does the model have the most trouble classifying?
A: 45% of misclassification occurs on images that contain facial hair.
Prior to the triggers the system will consist of several components: LFW[1] smart images which semantically describe who the image depicts and what Kumar [2] features the image in a similar to Image Snippet[6] and a visual concept ontology that describes a taxonomy of Kumar [2] features. Model test results will be loaded into the system and will be lifted to RDF. The system will then use an inference rule and the smart images to determine if an images within the test result are classified correctly or misclassified. For example if we get a test result that says image 203 is Steve Irwin, we can perform a query to get the ground truth data on image 203 and if that image depicts Steve Irwin, we will assert a new triple saying that the classification result is correct.Another inference rule will calculate the accuracy of classified images with an attribute by counting the number of correctly classified images with the attribute and dividing by all images with the attribute. This process will be repeated for each attribute and upper level term within the ontology of visual concepts to calculate accuracy. Afterwards another inferencing rule will examine the accuracies and provide a rating of great, good, ok, fair, bad. Finally we will display these results to the end user through the hierarchical view that shows the hierarchy of attributes/upper terms and the accuracy, ratings. The hierarchy view will start by displaying the results for the highest levels of the taxonomy tree and show every image and the accuracy overall, but the user will be able to select a lower level of the tree such as whether the photo used a flash, whether the subject is smiling or not, or, as listed in this competency question, whether or not the subject has facial hair, and the view will only show the results for photos that belong to that section of the hierarchy tree.
Q: What type of facial attributes does the model most associate with George W. Bush?
A: ‘White”, “appears masculine”, and “wearing tie” are most associated with George W. Bush.
Since the model test results are known, we can link them to our “smart” images that contain attribute tagging. From this we can look at all the images of George W. Bush that were classified properly using the LFW ground truth and count which attributes occur more frequently by running a SPARQL query counting the number of occurrences of each attribute in images that were classified as "George W. Bush" by the user’s model - for instance, “wearing necktie”. Then, using our ontology’s taxonomy structure for attributes, we can determine that this attribute is a type of “wearable.” We then display the results of these queries using the hierarchy view as mentioned before, only this time instead of showing the accuracy statistics and percentages we show the accumulated number of images that the model has classified as George W. Bush and contains one or more of the associated attributes (or sub attributes). The user is then able to look at the hierarchy to determine which attributes are most associated with George W. Bush at the level of detail that they are interested in. This query could work for any attribute we (using the Kumar features) or the model have tagged, be it the person’s name or an image attribute.
Q: Which of these two models is better at classifying people with long hair?
A: FaceNet is 10% better than dlib at classifying people with potentially long hair, aka not bald.
The system will load both models and compare the accuracy results generated using the inferencing rules for the long hair which is an upper ontology term which consists of images with the following attributes: Curly Hair, Wavy Hair, Straight Hair, and Bald. The model which produces the higher accuracy will be declared better at classifying people with long hair and the difference between the accuracies will be used to qualify the statement. However, because we do not have a suitably strong positive relationship between any of our attributes and the questions but do have a strong negative relationship — a matter that we are not going to be responsible for dynamically figuring out because this is far beyond our scope, instead it shall be hardcoded into the pre-arranged question selection — we can remove results that can’t possibly have long hair, bald people for example, and present the results as a potential solution built from the negation of the impossible options.
Q: How well would my model work at classifying mugshot-like photos?
A: The model has 90% accuracy on images that match labels that the user associated with mugshots.
Here the user wishes to evaluate the model’s use in a particular case. While the LFW images do not contain mugshots, the attributes do contain several attributes which appear in mugshot photos as well. The user enters in a list of attributes (some of which may be higher-level attributes in our taxonomy tree like “facial hair.” In the mugshot case these attributes would likely be “Harsh lighting”, “Posed photo”, and “Eyes open.” The system would then, using our ontological taxonomy tree, find all of the photos that are tagged with these attributes or fall into a higher level attribute such as “facial hair”. Then using an inferencing rule we will identify misclassification and calculate the models accuray on this subset of images. After calculating this accuracy another inferencing rule will rate the model great, good, ok, fair, or bad depending on the accuracy. Finally the system will display those results to the user in our UI.
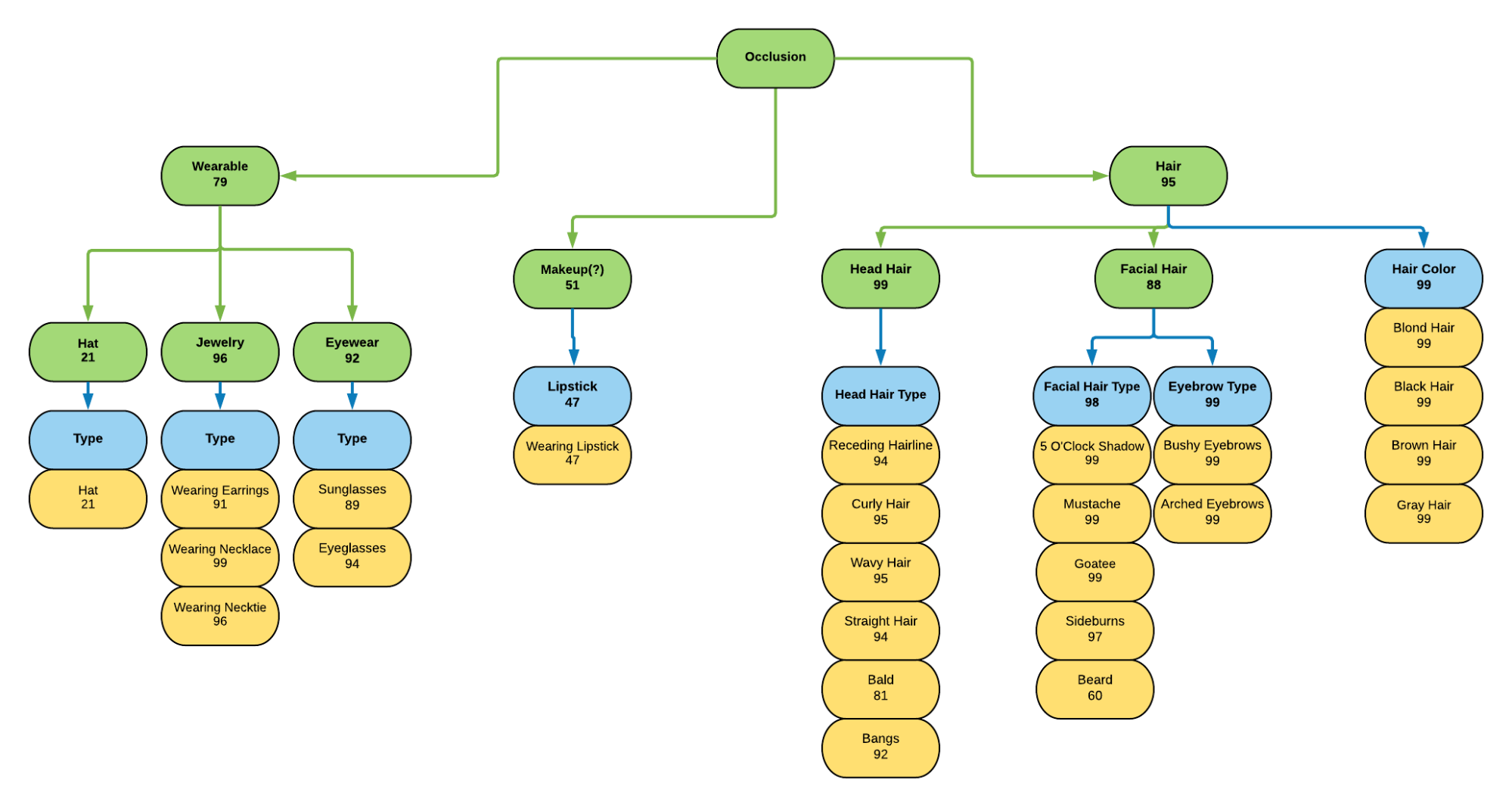
Q: What type of occlusions does my facial recognition model misclassify most?
A: Your model is most likely to fail when the eyes are covered.
We consider the above question to be semantically similar to, “What part of the face does my model have trouble handling when it is occluded?” In our model, we have defined Occlusion as a class. In addition, we have defined various subclasses of Occlusion that are differentiated by what part of the face they are blocking. When running a model’s result set with this question in mind, we will have access to the ground truth of what is truly correct, and access to what the model believes is correct. By comparing these, we will now have access to what classification the model in question got incorrect. Because we have specified that the models being used with our system must have been trained on the LFW training set, we also have access to what accessories, attributes, and — with a bit of inferencing— sources of occlusion are in an image. [Note that images are pre-tagged with what accessories a person is hearing. With that, we can do “insert-aforementioned-accessory-here” isOcclusionSourceOf “resultant-Occlusion”] Because the occlusions are associated with a specific region of the face, this means that you can now find the associated facial region. [“resultant-Occlusion” isOccludingBodyRegion “facial-region”] Throw in a couple sprinkles of math and now you have the answer.
VIII. Resources
Knowledge Bases, Repositories, or other Data Sources
Data | Type | Characteristics | Description | Owner | Source | Access Policies & Usage |
Labeled Faces in the Wild (LFW) | local | 13,000 labeled images of faces collected from the web | A database of labeled face images designed for studying facial recognition, along with the ground truth answers. It’s being used because it is a community standard in domain of facial recognition. | University of Massachusetts Amherst and NSF | http://vis-www.cs.umass.edu/lfw/index.html | NSF requires projects funded by them to share their data & UMass openly shares it |
LFW Attribute | local | ~77 macro attributes labeled on every image | Image attributes learned for every image within the LFW dataset. Image ids will overlap with allowing us to associate a attributes to an image. | Columbia University and NSF | http://www.cs.columbia.edu/CAVE/databases/pubfig/download/lfw_attributes.txt | Provided alongside LFW |
FaceNet | local | Has achieved an accuracy of 99.63% on LFW | A convolutional neural network model trained on the images from the LFW dataset. Image ids on test results will overlap with LFW ids allowing us to determine ground truth and attributes | https://github.com/davidsandberg/facenet/wiki/Validate-on-lfw | MIT License (unlimited copy, modify, merge, publish, …) | |
dlib | local | Has achieved an accuracy of 99.38% on LFW | A residual neural network model trained on the images from the LFW dataset | Davis E. King | https://github.com/davisking/dlib | Boost Software License - Version 1.0 - August 17th, 2003 |
External Ontologies, Vocabularies, or other Model Services
Resource | Language | Description | Owner | Source | Describes/Uses | Access Policies & Usage |
VoID | RDFS | An ontology to express metadata about a dataset | DERI/W3C | http://vocab.deri.ie/void#Dataset | VoID is used in over 77 other ontologies | Open |
VCO | OWL | An ontology that organize visual features in a hierarchical structure to described image content. | DISA | http://disa.fi.muni.cz/results/software/visual-concept-ontology/ | WordNet used to describe concepts within VCO | Open |
MLS | OWL | An ontology that can be used to represent and information on data mining and machine learning algorithms, datasets, and experiments. | W3C working group | None yet, it’s a new ontology working towards becoming a W3C standard | Open | |
LIO | OWL | An ontology that describes the visual features and attributes of any visual element | Image Snippet | http://www.imagesnippets.com/lio/lio.owl | Used by image snippet to tag images for smart searching | Open |
IX. References and Bibliography
[1] G. B. Huang, M. Mattar, T. Berg, and E. Learned-Miller, “Labeled faces in the wild: A database for studying face recognition in unconstrained environments,” in Workshop on faces in’Real-Life’Images: detection, alignment,
and recognition, 2008.
[2] F. Schroff, D. Kalenichenko, and J. Philbin, “Facenet: A unified embedding for face recognition and clustering,” in Proceedings of the IEEE conference on computer vision and pattern recognition , 2015, pp. 815–823.
[3] N. Kumar, A. Berg, P. N. Belhumeur, and S. Nayar, “Describable visual attributes for face verification and image search,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 33, no. 10, pp. 1962–1977, 2011.
[4] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in Computer Vision and Pattern Recognition, 2009. CVPR 2009. IEEE Conference on. Ieee, 2009, pp. 248–255.
[5] M. Johnson and A. Savakis, “L1-grassmann manifolds for robust face recognition,” in Image Processing (ICIP), 2015 IEEE International Conference on. IEEE, 2015, pp. 482–486.
[6] Imagesnippets. [Online]. Available: www.imagesnippets.com/
[7] D. E. King, “Dlib-ml: A machine learning toolkit,” Journal of Machine Learning Research, vol. 10, no. Jul, pp. 1755–1758, 2009.
[8] E. Learned-Miller, G. B. Huang, A. RoyChowdhury, H. Li, and G. Hua, “Labeled faces in the wild: A survey,” in Advances in face detection and facial image analysis. Springer, 2016, pp. 189–248.
[9] D. Silverstein and J. Farrell, “The relationship between image fidelity and image quality,” Proceedings of 3rd IEEE International Conference on Image Processing.
X. Notes
Model accuracy values are more specifically model accuracy on the LFW dataset. Obviously we cannot test the model on all possible images.
Both LFW and LFW Attributes contain ground truths for the ontology to use for computing accuracy.
Misclassifications associated with Occlusions
This is an example hierarchy view of the various forms of occlusion that occured in a test set. In this view, the user is given the various forms of expected occlusion organized into an “is-a” based tree. In the above diagram, the numbers in the circles are the percentage of misclassifications that have occured on an image that has been tagged with that attribute compared to the total tagged for that attribute. For example, exactly 47% of the images that are tagged as contained lipstick were correctly classified. Thus a person could assume that this was a major issue and it should be addressed, aka, receive a score of, “bad.” Only 82% of bald faces were correctly classified when the average for all forms of hair is 99, thus the model has an issue with bald people. We are currently considering adding inference rules for stings like statistical significance, bias, etc based on the essentials of research statistics.
Example Inferencing rules in Blazegraph
https://wiki.blazegraph.com/wiki/index.php/InferenceAndTruthMaintenance
RDFS10 is: (?u,rdfs:subClassOf,?u) <= (?u,rdf:type,rdfs:Class).
public class RuleRdfs10 extends Rule {
private static final long serialVersionUID = -2964784545354974663L;
public RuleRdfs10(String relationName, Vocabulary vocab) {
super( "rdfs10",
new SPOPredicate(relationName,var("u"), vocab.getConstant(RDFS.SUBCLASSOF), var("u")),
new SPOPredicate[]{
new SPOPredicate(relationName,var("u"), vocab.getConstant(RDF.TYPE), vocab.getConstant(RDFS.CLASS))},
null // constraints
);
}
}
Once you have written your own rule, you need to incorporate it into one of the "inference programs", typically the FullClosure program.
For example we could easily use this API to add additional rules such as:
Correct Classification by querying for Result classes that have a prov:value that matches to who the Image is prov:attributedTo
Accuracy Ratings by querying for accuracy and asserting a label {good, bad, okay} if were within some range
We haven't had a chance to implement any of these additional rules yet, but plan to in the near future.